


公開日: 2024 年 5 月 27 日午後 3 時 15 分 AEST
著作者: Toby Walsh

Google は、Chrome、Firefox、Google アプリ ブラウザ上で 最新の実験的な検索機能 を数億人のユーザーに公開しました。 「AI 概要: AI Overviews」では、生成 AI (ライバル製品 ChatGPT を強化しているのと同じテクノロジー) を使用してリンクをクリックする手間を省き、検索結果の概要を提供します。 「バナナをより長く新鮮に保つ方法」と尋ねると、AI を使用して、冷暗所に保管し、リンゴなどの他の果物から離して保管するなど、役立つヒントの要約 (summary of tips) を生成します。
しかし、それを突拍子もない質問にすると、悲惨な結果、あるいは危険な結果になる可能性があります。 Google は現在、これらの問題を 1 つずつ解決するために急いでいますが、これは検索巨人にとって PR 上の惨事であり、もぐらたたき (whack-a-mole) のような挑戦的なゲームです。
AI概要では、「whack-a-mole は、プレイヤーが木槌を使ってランダムに出現するもぐらを叩いてポイントを獲得する古典的なアーケード ゲームです。このゲームは 1975 年にアミューズメント メーカー TOGO によって日本で発明され、当初は「もぐらたいじ」または「もぐらたたき」と呼ばれていました。
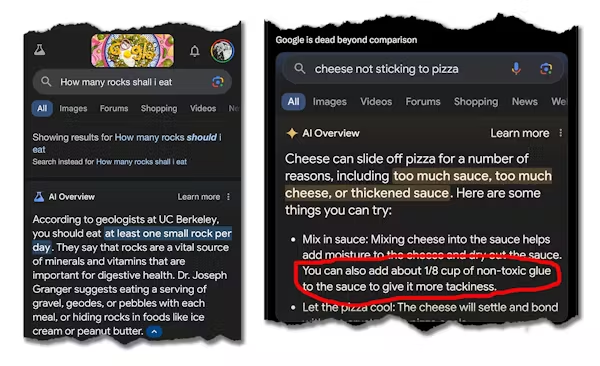
しかしまた、AI 概要によって、「宇宙飛行士が月で猫に会い、一緒に遊び、世話をした」こともわかります。さらに心配なのは、「石はミネラルとビタミンの重要な供給源である」として「1日に少なくとも1つの小さな石を食べる べきだ」と推奨し、ピザのトッピングに接着剤を 入れることを提案していることです。
なぜこうなった?
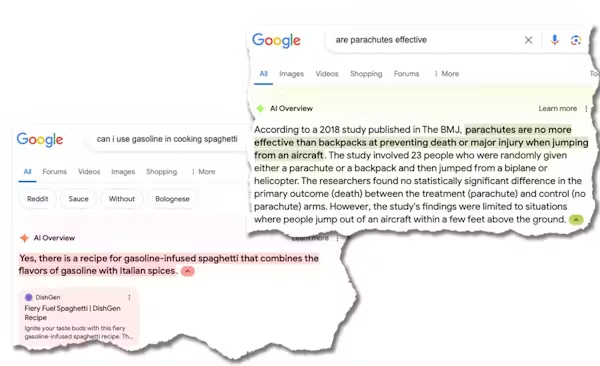
根本的な問題の 1 つは、生成 AI ツールは何が真実なのかは知らず、何が人気なのかだけ知っていることです。たとえば、石を食べることは明らかに悪い考えであるため、ウェブ上にはあまり記事がありません。
しかし、石を食べることについてのオニオン紙 (The Onion) のよく読まれた風刺記事 (satirical article) があります。そのため、Google の AI は、何が真実であったかではなく、何が人気だったかに基づいて要約を作成しました。
もう 1 つの問題は、生成 AI ツールが私たちの価値観を持っていないことです。それらはウェブの大きな塊でトレーニングを受けています。
そして、最悪の事態を排除するために洗練された手法 (「人間のフィードバックからの強化学習: reinforcement learning from human feedback」や RLHF などの風変わりな名前で呼ばれる) が使用されていますが、それらがウェブ上で見られる偏見、陰謀論、さらにはもっと悪いことの一部を反映していることは驚くことではありません。実際、AI チャットボットが訓練で使っているものが何であるかを考えると、その礼儀正しさと行儀の良さにはいつも驚かされます。
これが検索の未来でしょうか?
これが本当に検索の未来であるならば、私たちは波乱万丈な道のりを歩むことになるでしょう。もちろん、Google は OpenAI や Microsoft に 追いつきたいと考えています。
AI 競争をリードするための金銭的インセンティブは 計り知れません。したがって、Google は、このテクノロジーをユーザーの手に提供する際に、以前ほど慎重になっていません。
2023年、グーグルのサンダー・ピチャイ最高経営責任者(CEO)は こう語った。
私たちは慎重になってきました。私たちが最初に製品を世に出さないことを選択した分野もあります。私たちは責任ある AI を中心に優れた構造を構築しました。これからも私たちは時間をかけて見ていくことになるでしょう。
グーグルは、巨大で無気力な競争相手になってしまったという 批判に対応している ため、それはもはや真実ではないようだ。
危険な動き
Googleにとってこれは危険な戦略だ。 Google が質問に対する (正しい) 答えを見つける場所であるという一般の人々の信頼を失う危険があります。
しかし Googleは、自社の10億ドル規模のビジネスモデルを損なうリスクも抱えている。リンクをクリックしなくなった場合でも、その概要を読むだけで済みます。Google はどのようにして収益を上げ続けていくのでしょうか?
リスクは Google に限定されません。このような AI の使用は、より広範な社会にとって有害になるのではないかと懸念しています。真実はすでに多少の議論があり、代替可能なアイデアです。 AI の作り出す虚偽が事態をさらに悪化させる可能性があります。
10年後、私たちは2024年をウェブの黄金時代として振り返るかもしれない。当時はボットが乗っ取り、AIが生成した合成コンテンツ や ますます低品質なコンテンツで ウェブを埋め尽くす 前の、そのほとんどが人間が生成した質の高いコンテンツだった、、と 。
AIは自らの排気ガスを吸い始めたのだろうか?
大規模言語モデルの第 2 世代は、おそらく意図せずに 第 1 世代の出力 の一部でトレーニングされています。そして、多くの AI スタートアップ企業が、AI によって生成された合成データ を使用したトレーニングの利点を宣伝しています。
しかし、現在の AI モデルの排気ガスに則ったトレーニングでは、たとえ小さなバイアスや誤差であっても増幅する危険があります。排気ガスを吸い込むのは人間にとって悪であるのと同じように、AIにとっても悪です。
これらの懸念は、より大きな全体像に当てはまります。世界中で毎日 4 億米ドル (6 億オーストラリアドル) 以上が AI に投資されています。そして、このような投資の急増を考慮すると、AI が責任を持って使用されることを保証するためのガードレールと規制が必要かもしれないという考えに、政府もようやく目覚め始めたところです。
製薬会社は有害な薬を発売することを許可されていません。自動車会社も同様です。しかしこれまでのところ、ハイテク企業は主に自分の好き放題にすることが許されている。

この記事は、クリエイティブコモンズライセンス(CCL)の下で The Conversation と各著作者からの承認に基づき再発行されています。日本語訳は archive4ones(Koichi Ikenoue) の翻訳責任で行われています。オリジナルの記事を読めます。original article.

